准备工作
最新书稿已更新至 XQuant 量化课堂页。 想阅读最新版官方书稿,请前往图书页。
前言讲完了学习地图,这一章先把工作台搭起来。你要做两件事:第一,把 AI 编程工具和 Python 环境准备好;第二,用“装环境”这件事,完整练一次写 spec。
这一章先不要求你学会编程,也不要求你记住每一条命令。你只需要了解:把任务说明白是你的工作;让 AI 按说明执行;拿到结果后再检查对不对。本章会提供检查工具,帮你判断环境是否真的准备好了。准备工作做好了,从第 1 章开始,我们就可以直接跑量化实验。
先认识要用的工具
做量化实验需要的工具并不多。入门阶段先认识三类就够了:数据源、编程环境、AI 编程工具。先把这三类说清楚,后面安装时你就知道每一步在准备什么。
数据源:策略的原材料
数据是量化策略实验的原材料。没有历史价格、成交量这些基础数据,就没有根据提出策略,也无法检验策略是否有效。本书主要用两个免费数据源,如表 II-1 所示。
表 II-1 本书使用的数据源
| 数据源 | 覆盖范围 | 费用 |
|---|---|---|
| akshare | A 股为主,数据全、更新快 | 免费 |
| yfinance | 全球股票,接口简单 | 免费 |
你不需要提前下载一大包数据文件。后面运行代码时,程序会自己从网上获取数据。数据很重要:没有数据做不了实验;数据错了、缺失了、处理得不对,都会影响结论,进而影响最终判断。
数据中的问题有非常多细节,略举几例,暂时听不懂没关系,比如复权、停牌、幸存者偏差,后面遇到真实实验时再讲。
编程环境:跑代码的工作台
有了数据,还需要一个能运行程序的环境。程序写好了,要让它自动执行,需要安装一些“看不见”的软件,这在编程里叫“环境”。你可以把环境理解成厨房:数据是食材,环境是锅、灶、刀具和调料。没有这些东西,有食材也做不出饭。
我们需要的环境,是运行 Python 程序的一组工具,比如 Python 解释器、Jupyter Notebook 等。你不用先记住这些名字,后面我们会让 AI 帮你把它们装好。你不需要 GPU、云服务器或数据库,一台普通电脑就够了,操作系统是 Windows、macOS 或 Linux 都可以。
本书用到的基础环境如表 II-2 所示。
表 II-2 本书使用的编程环境
| 工具 | 用途 |
|---|---|
| Python 3.12 | 运行代码的语言 |
| Jupyter Notebook | 边写边看结果的交互式环境 |
| 常用库 | pandas、NumPy、Matplotlib 等现成工具 |
表里的“库”,可以理解为别人已经写好的工具包。比如 pandas 负责处理表格数据,Matplotlib 负责画图。你不需要详细学习这些工具,只要把它们装好,AI 懂得用就行。
第 2 章起,本书还会用到一个叫 open-xquant 的开源量化框架,它是我们自己专门为 AI 写的一个框架,等到第 2 章正式介绍它。这一章只负责把它先装进环境里。
AI 编程工具:把 spec 变成代码
前言里说过,你不需要先学会编程再学量化,但你必须学会把策略描述清楚,把它写成策略规格说明书,简称 spec。AI 编程工具的作用,就是把你写清楚的 spec 翻译成 Python 代码,再帮你运行和修改。
主流 AI 编程工具不少,如表 II-3 所示。
表 II-3 主流 AI 编程工具对比
| 工具 | 简介 |
|---|---|
| VS Code + Copilot | 老牌编辑器,加装 AI 插件 |
| Cursor | 使用广泛的 AI 编程工具 |
| Claude Code | Anthropic 出品的 AI 编程工具 |
| Codex | OpenAI 出品,专业开发者常用 |
| OpenCode/OpenClaw | 开源的 AI 编程工具 |
| TRAE | 字节跳动出品,AI-first 设计,中文界面 |
这里要区分两个容易混淆的概念:编程工具和编程模型。表 II-3 里的都是编程工具,是你直接操作的界面;编程模型则是工具背后的能力来源。很多编程工具都可以切换或配置不同模型。具体哪个模型更适合写代码,会随着产品迭代不断变化,你不需要在这里记住某个固定名单。
本书以 TRAE 为演示工具,原因很简单:中文界面、上手门槛低、SOLO 模式围绕“和 AI 对话”设计。对零基础读者来说,这比先学一个复杂编辑器更友好。TRAE 还在不断迭代,也许你看到这本书时,产品界面已经不一样了,我相信,这些 AI 编程工具只会越来越容易使用,而不是越来越难。
如果你已经有自己熟悉的 AI 编程工具,我鼓励你继续使用自己的工具,因为本书并不是教你学会一个静态的工具,而是学会一种思维模式。后面的关键不是某个按钮在哪里,也不是要记住某个具体命令,而是学会使用 AI 来实现自己的投资想法、检验自己的投资想法,这比学习工具本身重要得多。
本书截图主要覆盖 macOS 和 Windows。如果你使用 Linux,书中的思路仍然适用,但个别安装命令、界面位置和系统权限提示可能需要按你的发行版调整。
接下来的安装顺序会和上面的介绍略有不同:我们先装 AI 编程工具 TRAE,再让 TRAE 帮你装 Python 环境和这些库。这样做的目的,是让 AI 从第一步开始就参与进来。
安装并设置 TRAE
我们这一步只做三件事:下载并安装 TRAE,切到适合本书的 SOLO 模式,再打开一个学习目录。
下载并安装 TRAE
访问 TRAE 官网 trae.cn 或 trae.ai,根据你的操作系统下载安装包。下载页面如图 II-1 所示。
下载完成后运行安装包。Windows 用户按安装向导提示继续,安装界面如图 II-2 所示;macOS 用户把 TRAE 拖入应用程序,安装界面如图 II-3 所示。
切到 SOLO 模式
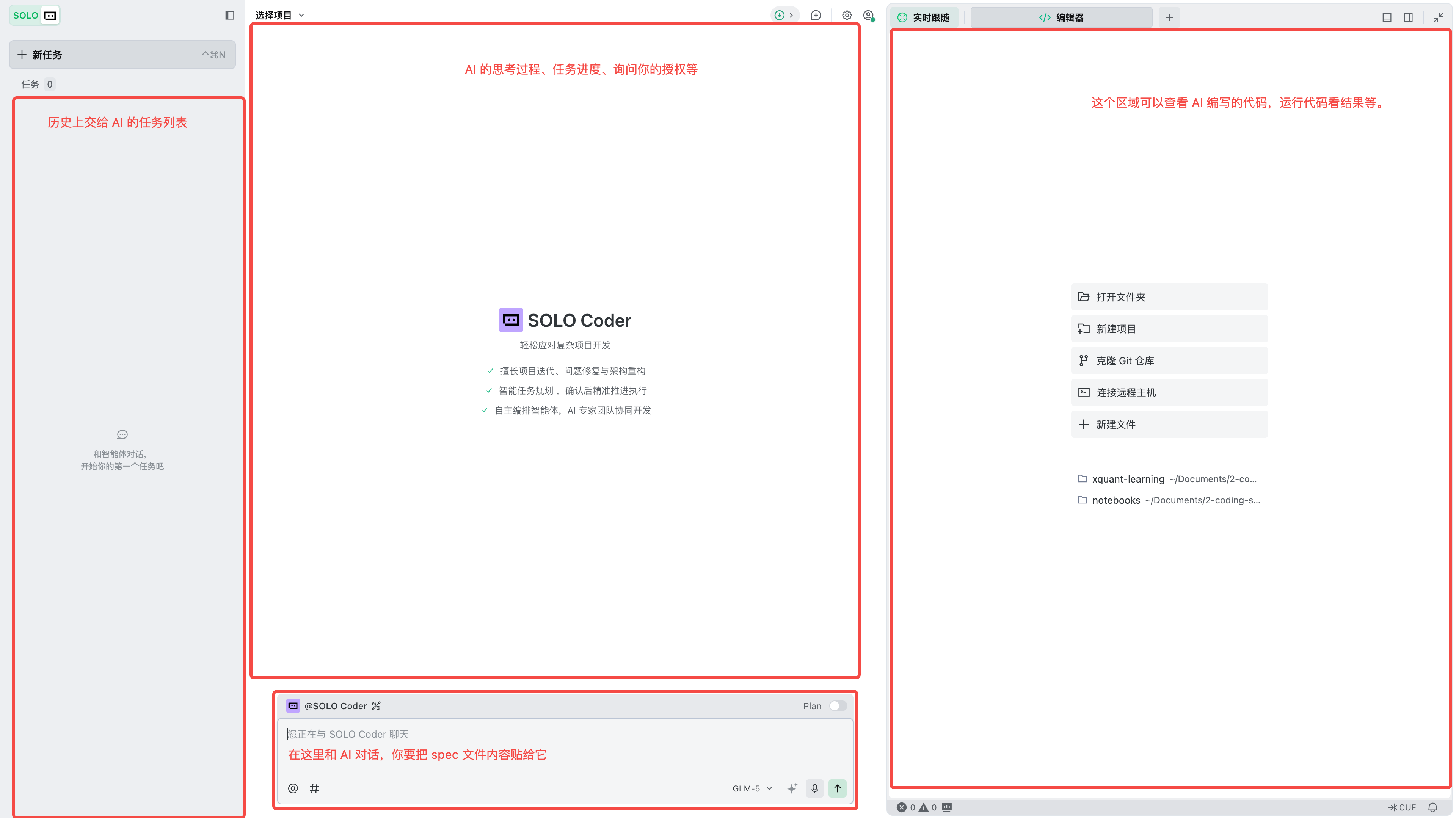
安装完成后打开 TRAE。默认界面可能是 IDE 模式,如图 II-4 所示;本书使用的是 SOLO 模式,它更像“和 AI 一起完成任务”的工作台。
切到 SOLO 模式后,界面会变成图 II-5 这样。你最需要关注的是下方的 AI 对话框:后面所有 spec 都会粘贴到这里,让 AI 执行。
选择编程模型
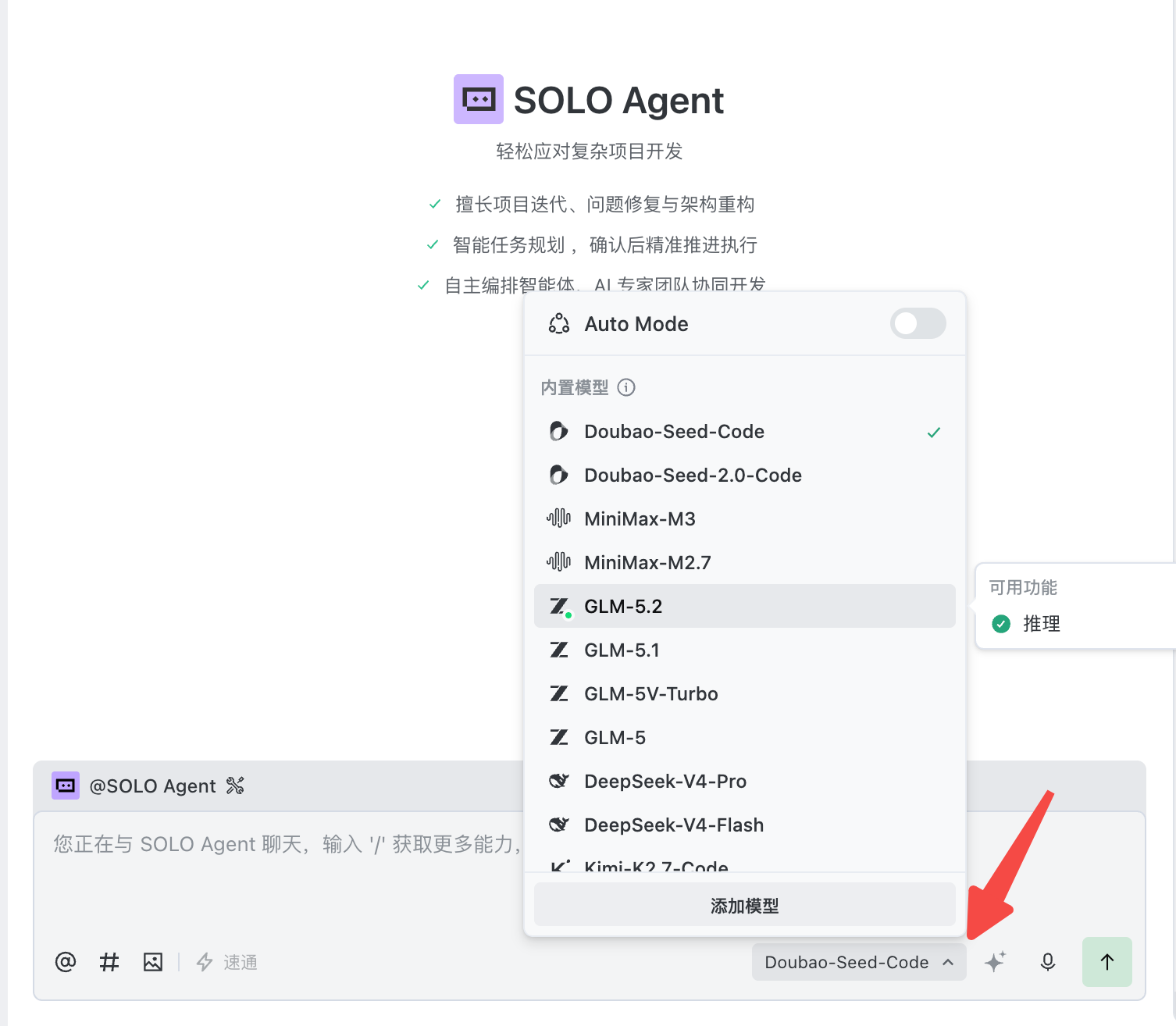
TRAE 已经内置了多个编程模型,入门阶段直接使用内置模型即可,不需要一开始就购买或配置额外模型。模型选择界面如图 II-6 所示。
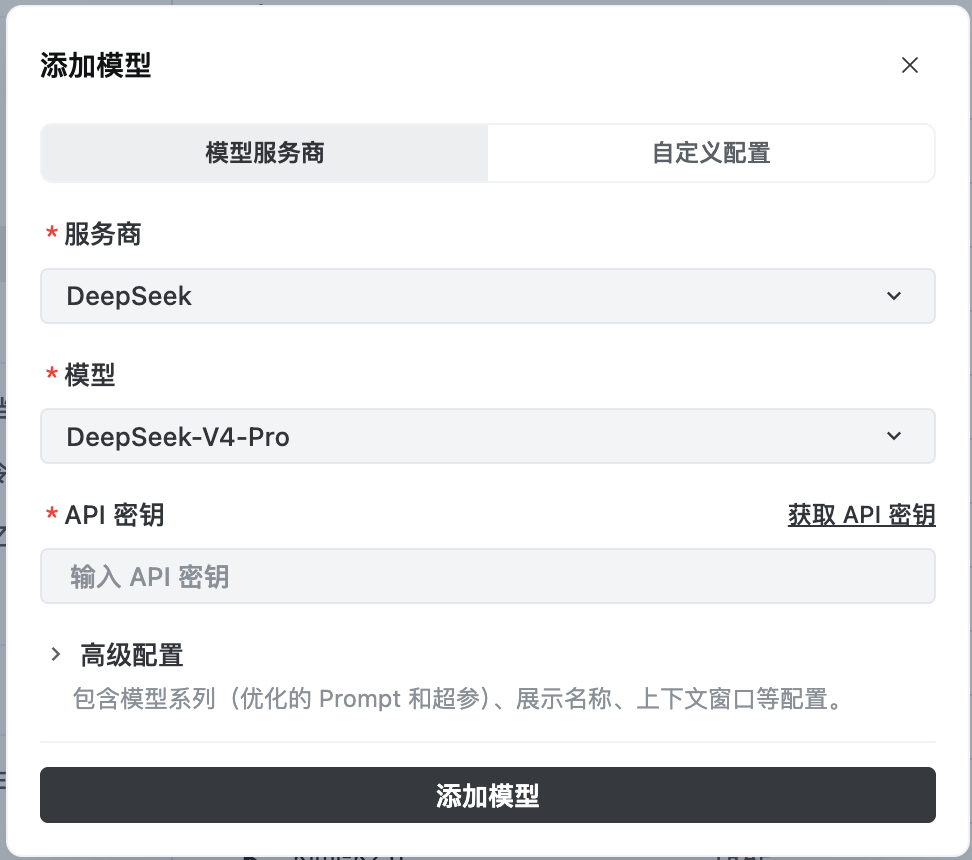
如果你已经有某个模型厂商的 API Key,也可以把它配置到所选的编程工具中。例如,你在 DeepSeek 的 API 平台购买了额度,就可以在后台创建 API Key,再填入 TRAE 的自定义模型配置。TRAE 的自定义模型配置界面如图 II-7 所示。
这里要搞清楚订阅账号和 API 账号的区别。ChatGPT Plus、Claude Max 这类订阅账号,通常是给用户本人在官方产品里直接使用的,不能直接填进“API Key”输入框。AI 编程工具如果要调用外部模型,通常需要 API 账号生成的 API Key;也有一些工具会提供官方登录或订阅集成,具体以工具自己的说明为准。入门阶段先用 TRAE 内置模型即可,后面确实需要更换模型时,再理解 API Key 也不迟。
创建并打开学习目录
在电脑上新建一个文件夹,作为本书的学习目录。建议使用英文路径,比如桌面上的 xquant-learning 文件夹,避免中文路径、空格或特殊符号带来额外问题。
然后在 TRAE 中打开它:菜单 → 文件 → 打开文件夹 → 选择 xquant-learning。操作过程如图 II-8 所示。
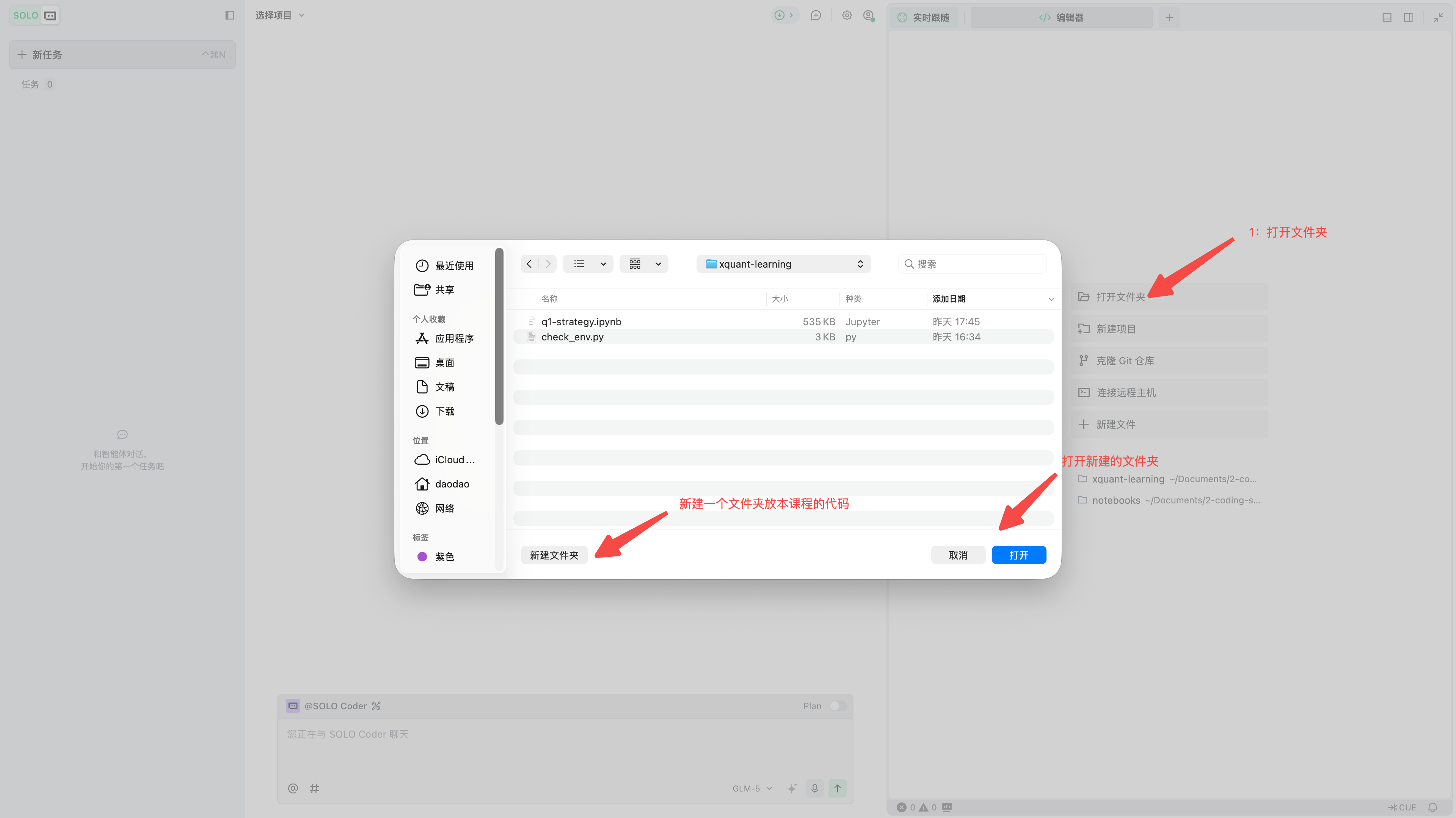
打开后,你会在左侧文件管理器中看到 xquant-learning 这个文件夹。现在它还是空的,下一步 AI 会帮你把需要的环境和文件创建出来。
让 TRAE 帮你搭建环境
到这一步,AI 编程工具准备好了,但 Python 环境还没准备好。我们的目标是把环境搭建好:装好 Python 3.12,装好本书要用的 7 个库,并用一个检查脚本确认环境真的可用。
最直接的想法,是告诉 TRAE:“给我装一下 Python 环境。”
这样不够。这里先约定一下:后面为了行文简洁,我们会把 AI 编程工具简称为 AI。它不知道你要哪个 Python 版本,用什么工具装,要装哪些库,也不知道怎样才算装对。你可能也不知道这些细节,这很正常;刚开始我会帮你把它们写清楚。
前言里讲过,spec 本身泛指一切要交给 AI 执行的任务说明书。这一章,这个任务就是搭建环境,以后的内容就专门指策略规格说明书了。本章的 spec 要说清楚的是:做什么、怎么做、做到什么程度算成功。
这份完整 spec 已经放在配套仓库里。你可以直接复制运行,但我们也从现在就在这个例子中看懂它为什么这样写。下面我们先看骨架,再一段段拆解。
写安装 spec
我们可以先想象一下,如果有人给我们布置一项任务,那么我们希望他怎么描述这项任务,才能让我们一次搞定的概率最高?同样的,我们把 AI 也看做一个人,一份能让 AI 高概率一次性完成的 spec,通常要回答四个问题:
📌 spec 的四段骨架
上下文 —— 所有跟这个任务有关的信息、背景知识。
任务描述 —— 任务具体要做什么,具体而明确。
任务要求 —— 任务要遵守的规范,满足的约束,遵循的原则等。
验收标准 —— 任务完成时要交付的清单,要满足的标准,清晰可检验。
注意第四段“验收标准”不是让你提前知道运行结果,而是先把成功标准写清楚。以这次环境搭建为例,“看到 11/11 全部通过,并且有 .venv/ 和 check_env.py”,这就比“装好了”清楚得多。
下面四段都以 macOS 为例。Windows 用户不用担心,这次要搭建的环境是跨平台的,而且 spec 的四段骨架完全相同,只需要在上下文中把 macOS 换成 Windows,把 mac 命令换成 PowerShell 命令即可。具体对应关系已经写在 specs/spec-01-env-setup-windows.md 里。
第一段:上下文
上下文段告诉 AI:现在是什么状态。我们刚装好 TRAE,打开了一个空目录,Python 和课程要用的库都还没装。这一段可以这样写:
上下文:我刚在 TRAE 中打开了一个空目录作为量化课程学习实践的根目录。本机是 macOS,尚未安装 Python 或课程要用的库。这是课程的第一份 spec,后续 spec 都依赖这一份装出的环境。
📌 要点 1:能一句话说清,就不要写两句
AI 关注的是指令,不是字数。写得越啰嗦,关键要求越容易被淹没。写 spec 的过程,本质上是在删掉多余的话,只保留真正重要的信息。
第二段:任务描述
任务描述段要一句话说明目标,不要把所有步骤塞进去。这里先补一个小词:uv 是一个管理 Python 环境的工具,它可以帮我们安装 Python、创建虚拟环境、安装库。
这次任务可以这样写:
任务描述:在当前目录下完成 macOS 量化课程编程环境配置:安装 uv,用 uv 创建 Python 3.12 虚拟环境,安装 jupyter、pandas、NumPy、Matplotlib、akshare、yfinance、open-xquant,并创建、运行
check_env.py检查脚本。
📌 要点 2:关键对象要点名
“装 Python”不够,要写成“Python 3.12”;“装一些库”不够,要把 7 个库的名字列出来;“写个检查脚本”不够,要写出文件名
check_env.py。关键对象越明确,AI 越不容易按自己的偏好补全。
第三段:任务要求
任务要求段是 spec 的主体。它把任务拆成可以执行的步骤。环境配置一共 6 步:确认目录、安装 uv、创建虚拟环境、安装库、创建检查脚本、运行检查脚本。
完整命令和 check_env.py 全文都在配套仓库的 specs/spec-01-env-setup-mac.md 里。书里先摘出开头几步,让你看清写法:
任务要求:
确认当前目录:运行
pwd,记录路径,后续所有操作都在这个目录下进行。安装 uv:运行
curl -LsSf https://astral.sh/uv/install.sh | sh,再运行source $HOME/.local/bin/env,最后用uv --version检查是否安装成功。创建 Python 3.12 虚拟环境:运行
uv venv --python 3.12,再激活虚拟环境,并用python --version确认版本。安装 7 个库:按 spec 文件中的版本号安装 jupyter、pandas、NumPy、Matplotlib、akshare、yfinance 和 open-xquant。
创建
check_env.py:把 spec 文件中的检查脚本写入当前目录。运行检查脚本:执行
python check_env.py,查看检查结果。
这里有个细节很重要:安装库时要锁版本号。比如不要写:
uv pip install pandas numpy matplotlib而要写成:
uv pip install pandas==3.0.* numpy==2.4.* matplotlib==3.10.*不锁版本,半年后某个库升级,书里的代码可能就跑不出来。锁到 ==X.Y.*,意思是小修小补可以升级,但大版本变化先不要碰。
📌 要点 3:会变化的东西要锁住
库版本会变,日期窗口会变,随机数也可能变。量化实验最怕今天能跑、明天不能复现。凡是会随时间漂移的关键条件,都要尽量写死。
第四段:验收标准
最后一段写成功标准。你还没有运行,怎么知道成功长什么样?答案是:你不用猜最终数据,只要约定检查脚本应该给出哪些信号。
比如这次我们要求看到 11/11 全部通过,要求命令退出码为 0,要求目录里出现 .venv/ 和 check_env.py。这些都是 AI 和你都能核对的信号。
验收标准:
python check_env.py最末两行输出:text结果: 11/11 全部通过! 环境配置完成,可以开始课程。命令退出码为 0。
当前目录下存在
.venv/目录与check_env.py文件。
📌 要点 4:成功标准要能检查
“看起来没问题”不算成功标准。更好的写法是给出具体数字、具体文件名、具体输出文字。这样 AI 做完后,你不用凭感觉判断,对照检查就行。
四段拼起来,就是一份完整安装 spec。下一节我们把真实文件交给 TRAE 执行。
让 TRAE 跑这份 spec
上一节我们已经看懂了安装 spec 的结构,现在要让 TRAE 来执行这一份任务说明书。打开文件之前,先看一个提示,等下看到弹窗就不会慌。
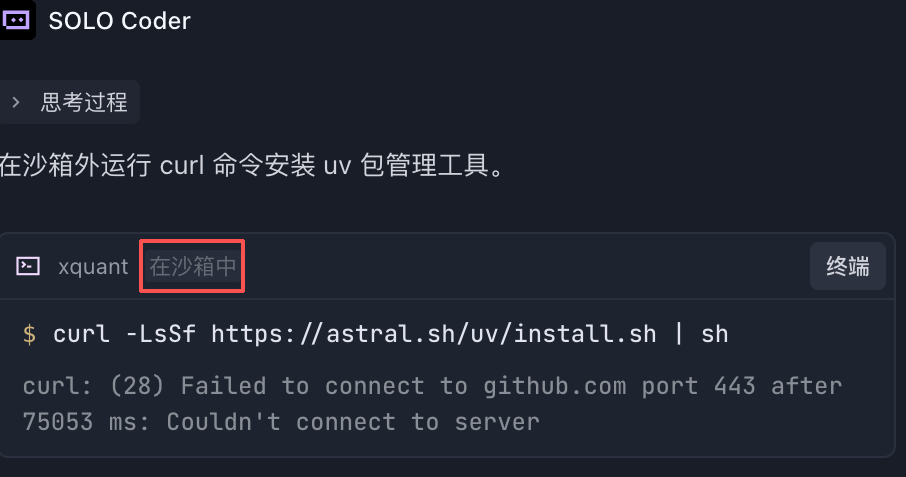
💡 提示:关于“沙箱”
TRAE 帮你装环境时,可能会询问是否允许“在沙箱外运行”。所谓“沙箱”,就是给 AI 的操作设置一个受限制的运行范围,用来降低误操作影响真实文件和系统环境的风险。但这次要安装的 Python 环境需要访问你的真实终端和学习目录,所以通常需要允许它在终端中运行。遇到这个提示,选择“是”“允许”或“在终端中运行”即可。过程示意如图 II-9 所示。
现在打开你系统对应的 spec 文件:
- macOS 用户:打开
specs/spec-01-env-setup-mac.md - Windows 用户:打开
specs/spec-01-env-setup-windows.md
把 spec 的全部内容复制到 TRAE SOLO 模式下方的 AI 对话框中,发送。
TRAE 会按 spec 自动完成 6 个步骤:安装 uv、创建虚拟环境、安装 7 个库、创建 check_env.py、运行检查脚本。整个过程通常只需要几分钟。你不需要理解每一条命令,只需要看最后的检查结果。
验证结果
如果一切顺利,你会在 TRAE 的终端中看到类似这样的输出:
==================================================
XQuant 课程环境检查
==================================================
[OK ] Python 3.12.x
[OK ] 虚拟环境已激活
[OK ] jupyter
[OK ] pandas
[OK ] numpy
[OK ] matplotlib
[OK ] akshare
[OK ] yfinance
[OK ] open-xquant
[OK ] jupyter 命令可用
[OK ] akshare 数据源连通(获取到 5847 条数据)
--------------------------------------------------
结果: 11/11 全部通过!
环境配置完成,可以开始课程。实际终端输出如图 II-10 所示。
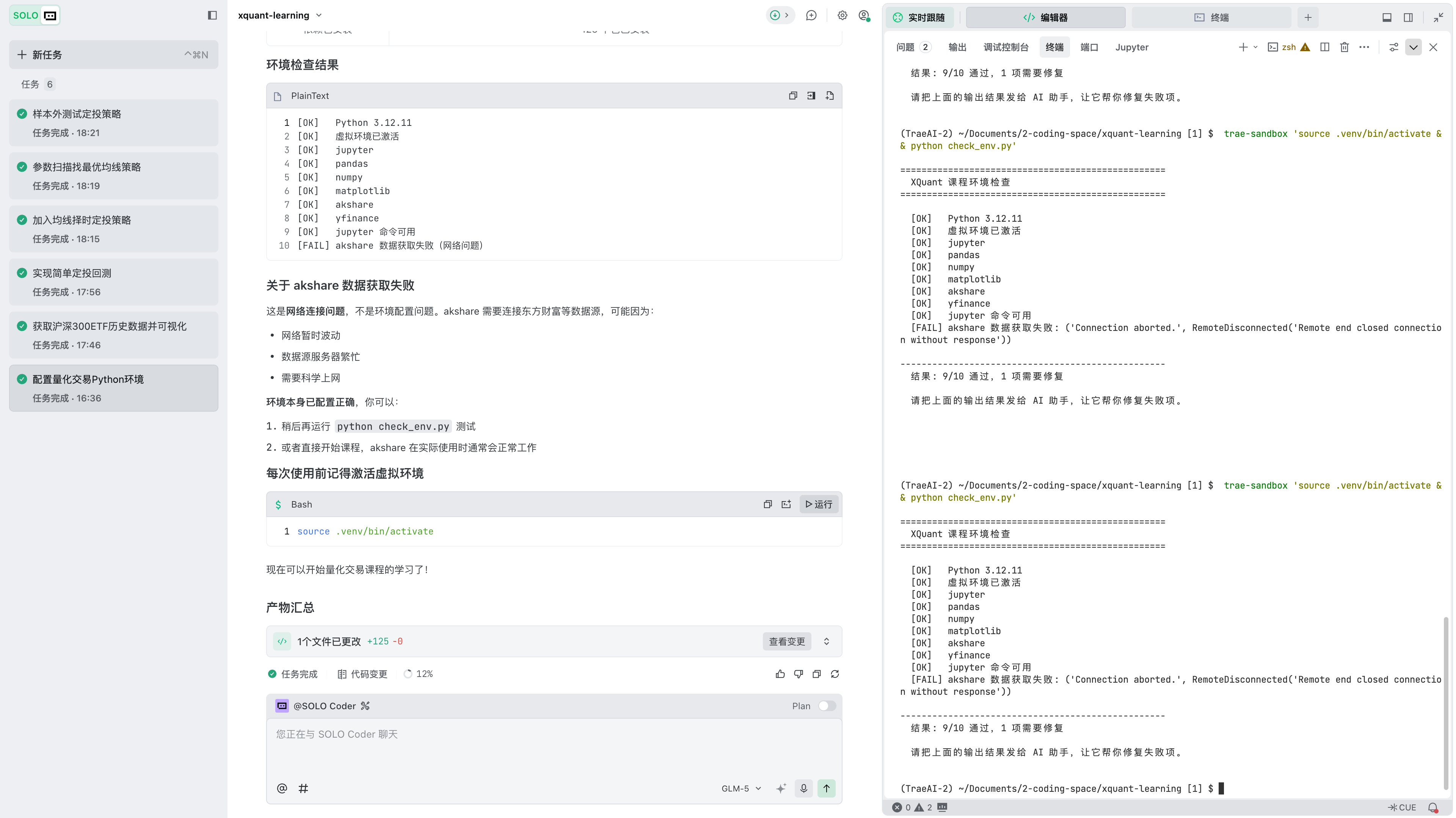
其中 akshare 数据源连通 后面的条数可能和书里不同,这不影响结果。关键是这一项显示 [OK],并且最后出现 11/11 全部通过。
如果有任何项目显示 [FAIL],不要自己改命令重试。把完整输出复制给 TRAE 的 AI 助手,告诉它:“环境检查有失败项,请帮我修复。”AI 会按照 spec 里的故障恢复说明逐项排查。
💡 关于错误处理
整本书你都不必去啃 Python 报错。遇到报错,把完整信息复制给 AI 助手就好。你的工作是写清楚任务、看懂结果;调试细节先交给 AI。
你刚刚学到了什么
刚才这个过程包含两件事。
第一,环境准备好了。这件事做完后,后面章节就可以直接跑实验。
第二,你看到了一份 spec 是怎样写出来的。它不是一段模糊、碎片、随意的说法,而是由上下文、任务描述、任务要求、验收标准四段组成。你把任务说清楚,AI 才能稳定执行。
7 条 spec 自查清单
把本章的 4 条要点,再加上后面会反复用到的 3 条补充,就得到一份 spec 自查清单。以后每写完一份 spec,都可以用它快速扫一遍。
表 II-4 spec 自查清单
| 序号 | 自查项 |
|---|---|
| 1 | 四段都齐了吗? 上下文、任务描述、任务要求、验收标准,一段都不能少 |
| 2 | 任务能一句话说清吗? 先讲目标,不要把所有步骤塞进任务描述段 |
| 3 | 关键对象准确吗? 如版本号、库名、文件名等,都要写清楚 |
| 4 | 会变化的条件确定了吗? 库版本、日期范围、随机种子,都要写清楚,不要变 |
| 5 | 成功标准能检验吗? 给出具体输出、具体文件、具体数字 |
| 6 | 指令是正向的吗? 多写“请做 X”,少写“不要 Y” |
| 7 | 长度是否合理? 不要因为详细,就写得啰嗦,都写必要而准确的话 |
写 spec 不需要死记硬背,多写多实验,多和 AI 交互自然能掌握。模型越强,越能对 spec 容错,但把 spec 写清楚,仍然能减少返工,也能让你更容易判断 AI 有没有做对。后面进入策略实验时,open-xquant 也会帮你检查策略规格说明书里常见的遗漏。
准备就绪
前言和这一章涉及的核心概念,汇总在表 II-5 里。
表 II-5 准备工作核心概念速查
| 概念 | 含义 | 这一章怎么用 |
|---|---|---|
| spec(任务说明书) | 给 AI 的结构化指令 | 用装环境练第一份 spec |
| spec 四段骨架 | 上下文 / 任务描述 / 任务要求 / 验收标准 | 按四段写清楚任务 |
| TRAE | 本书演示用的 AI 编程工具 | 把 spec 交给它执行 |
| Python 环境 | 跑代码需要的语言和库 | 用检查脚本确认可用 |
| 四个阶段 | 确定候选 / 制定规则 / 执行交易 / 评估归因 | 第 1 章开始正式进入 |
| 做 / 看 / 疑 | 写成规格 / 读懂结果 / 检验可信 | 本章先练“做”:把任务写清楚 |
到这里,你已经具备了开始学习量化交易的基本条件:有 AI 编程工具,有 Python 环境,也知道一份 spec 应该怎样写。
第 1 章,我们会用一个真实 ETF 走一遍完整流程:写规则、跑实验、看结果,以及让你产生第一次怀疑,为什么看到实验结果漂亮不要高兴得太早。准备好了吗?翻到下一章,开始第一次量化实验。